I have done a lot of work with Tenable over the last five years and achieved some really awesome results with the Tenable product suite, however, recently I was helping a customer with the slightly too frequent issue where Tenable broke their network.
Here’s what went wrong and the fix in this situation…
Tenable is a powerful tool and we all know that with power comes responsibility. The issue here isn't with the Tenable product or in the environment it was deployed to, but simply an oversight of how the two would interact. In the below network diagram you can see the network topology and how Tenable was deployed within it.
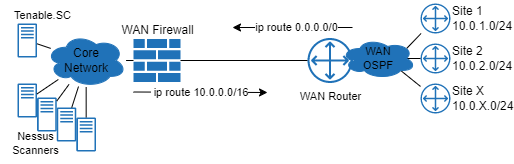
Take note of the how the routing has been configured especially the two static routes shown.
- The WAN firewall routes the 10.0.0.0/16 towards the WAN routers and redistributes that into OSPF with the core network.
- The WAN routers have a static default route back towards the WAN firewalls and redistributes that to OSPF with the ~60 remote sites.
The customer had been using Tenable.sc with a bunch scanners for a number of years now and the initial deployment was focused on scanning assets within their DCs and DMZ environments. With the appropriate number of scanners deployed in the right locations this had been working a treat with scans completing in the desired timeframes and good coverage of the target environment.
The Issue
Recently additional scanners were deployed into the DC to provide the capacity to extend their scans to the WAN networks. The existing scans used in the DC were duplicated and updated to target new asset lists which cover the WAN sites. New credentials had been added and tested against one or two IPs and the network team had added the required firewall rules to the WAN firewall. With the right approval, the schedule for the scans was enabled and the discovery scan would start at 10am the next day.
The discovery scan was configured to scan the entire 10.0.0.0/16 allocated to the WAN sites. As a result of when the scan kicked off, all the scanners in the DC were allocated to the scan and started scanning loads of IPs that didn't exist. Connections were allowed through the firewall and forwarded to the WAN routers, and then back to the firewalls. This loop quickly consumed all the firewalls resources and forcing production traffic to be dropped.
The Fix
With my knowledge of their environment and experience with Tenable the customer asked me to look at the department and provide a fix that would prevent this situation from happening again. After getting a handle on the exact details of the issue we implemented two solutions to prevent this happening again.
1. Route to NULL
To address the possible route loop between the firewall and WAN routers we added a NULL route on the WAN routers for the allocated WAN network range.
1
ip route 10.0.0.0 255.255.0.0 Null0
This route serves two purposes:
- The first is to efficiently drop traffic for any prefix that doesn’t exist on the WAN. More specific site prefixes are through OSPF from each WAN site to maintain a valid path to the site.
- Secondly, a similar effect, dropping traffic, occurs when monitoring tools are polling a WAN site that is currently down - a really fast polling monitoring system could cause similar issues to what we saw here.
2. Site based discovery scans
Our next change was to remove the 10.0.0.0/16 subnet from the discovery scan target list. Replacing the /16 with each sites specific prefix creates a bit of ongoing admin overhead but stops the scan generating the problematic traffic in the first place, and massively cuts down the total time taken for the discovery scan to complete.
To help with the addition of site specific asset lists, I grabbed an existing PowerShell script I had, made a few updates for their environment and we quickly had all the asset list built out. The script added a series of tags to the asset lists which made associating the right asset list to the scans super easy.
The take away
In the perfect situation, scanners would be deployed to each site removing the need to scan across the WAN completely and be in line with best practices, however no environment is perfect! Without infrastructure or the infrastructure capacity at each site the development topology was the best fit for their environment.
You can’t just think about how you will implement your Tenable deployment, you have to consider how it will interact with the environment. Every environment will dictate a different deployment and will need to be tailored to fit the environment correctly in order to avoid issues like this situation which can give an amazing product a bad name.